메시지 처리율 12%, 48,573건 유실. Queue 분리와 파티셔닝으로 Delivery avg 0.33ms를 달성한 과정.
에러 없이 죽는 시스템
1000VU 부하테스트에서 시스템은 에러 로그 하나 없이 무너졌습니다. Consumer 처리량이 0으로 수렴하면서 48,573건의 메시지가 Redis Stream에서 잘려 나갔고, 그 사실을 알게 된 건 Datadog 대시보드의 Processing Rate가 12%로 찍혀 있는 걸 보고 나서였습니다.
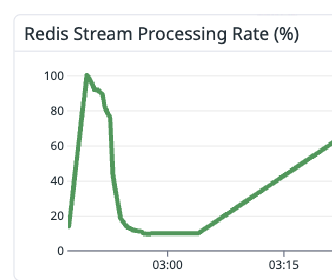
원인은 Pool Starvation이었습니다. Redis 커넥션 풀 8개를 Publisher(메시지당 7회 borrow)와 Consumer(메시지당 2회 borrow)가 나눠 쓰고 있었는데, Publisher는 스레드가 수백 개이므로 대기해도 다른 스레드가 이어갑니다. Consumer는 스트림당 단일 스레드 — Pool에서 대기하는 순간 그 파티션 전체가 멈춥니다. maxWaitMillis 기본값은 -1(무한 대기). 타임아웃이 없으니 예외도, 로그도 발생하지 않습니다.
Pool 크기를 늘리는 건 미봉책에 불과했습니다. 수요가 용량의 몇 배를 초과하는 구조에서는 수요 자체를 줄이는 아키텍처 변경이 필요했습니다.
초기 구조: 모든 것이 한 스레드에
초기 설계에서는 Tomcat 스레드 하나가 DB INSERT → Redis XADD → ReadState UPSERT → 참여자 조회를 순차 수행했습니다. Netty 전환을 먼저 검토했지만, JDBC가 동기 API인 이상 DB 구간의 blocking은 해결되지 않습니다. 인프라 전환 없이 코드 레벨 비동기화부터 시도하기로 했습니다.
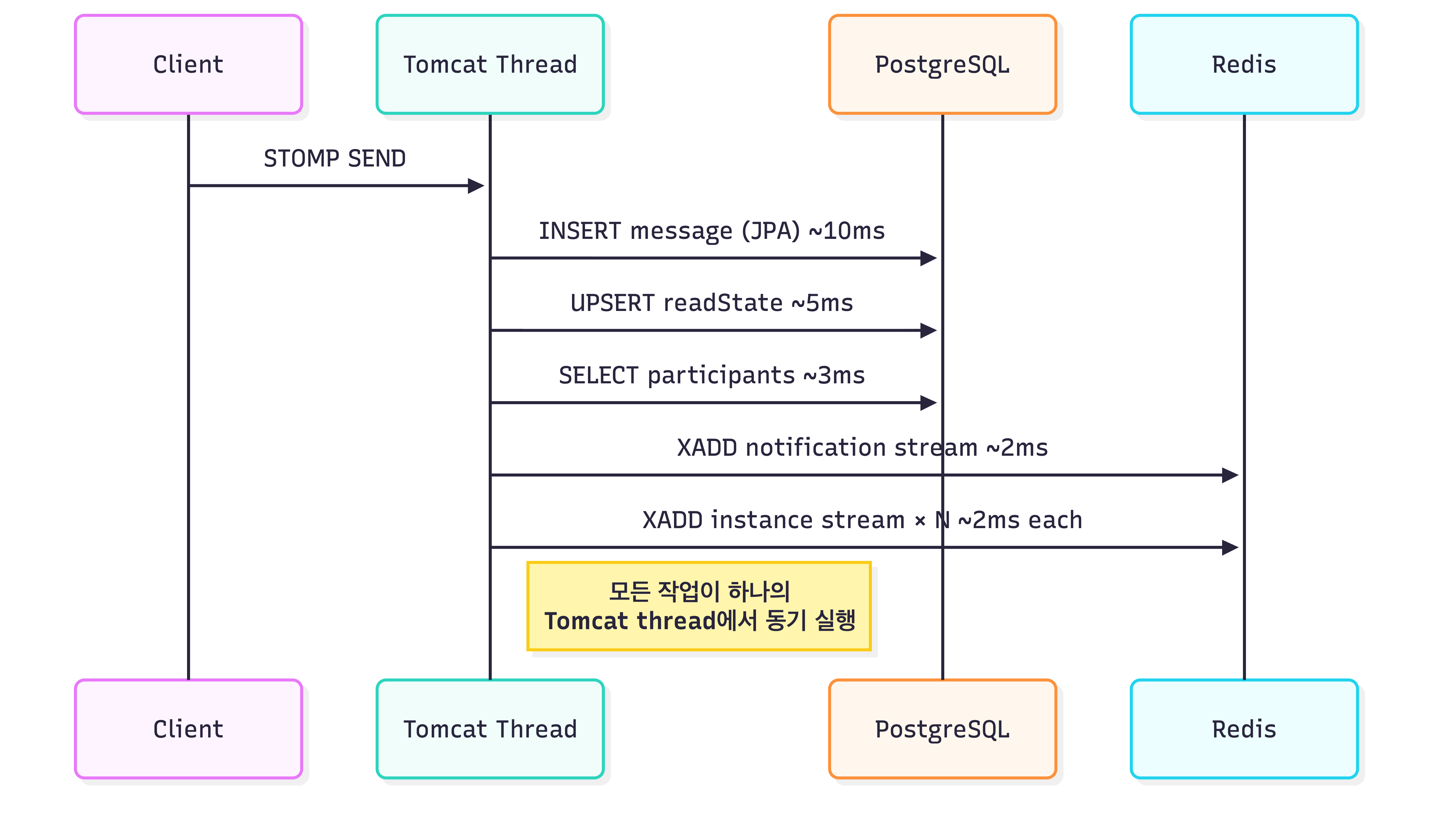
XADD-first: Producer에서 DB를 제거하다
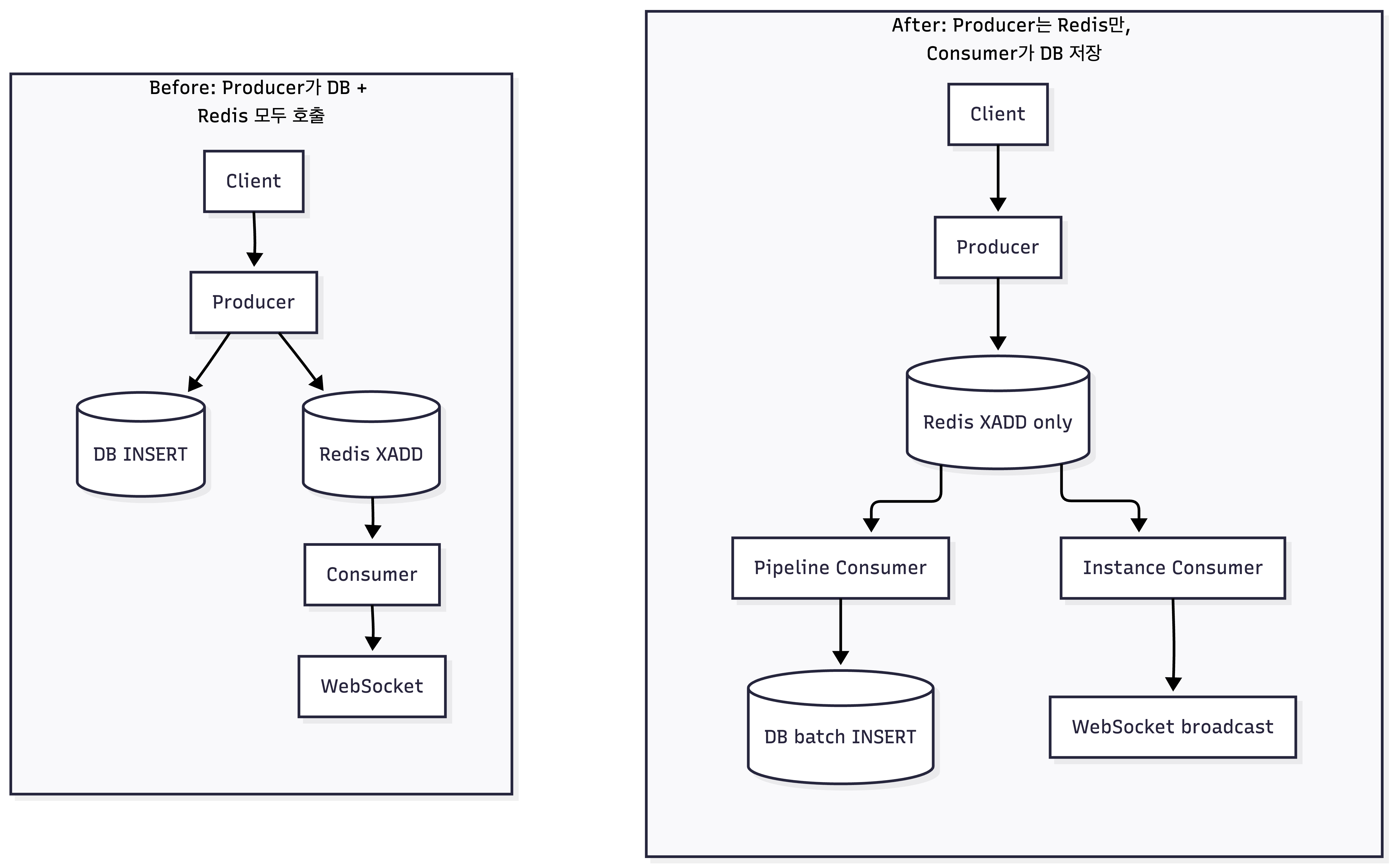
핵심 아이디어는 Redis Stream을 WAL(Write-Ahead Log)로 사용하는 것입니다. Producer는 Redis에만 쓰고, Consumer가 나중에 DB에 저장합니다. XACK를 DB save 성공 이후에만 호출하면, 실패 시 PEL(Pending Entry List)에 남아 자동 재시도됩니다.
Producer가 DB에 접근하지 않으니 auto-increment ID를 쓸 수 없습니다. UUID(Lua 호환성 문제), Snowflake(복잡도 대비 이점 불명확)를 검토한 끝에 Redis INCR을 채택했습니다. ID 발급과 채팅방 최신 메시지 갱신을 하나의 Lua 스크립트로 합쳐 1 roundtrip으로 처리합니다.
-- combined-publish.lua: 2 roundtrips → 1 roundtrip
if redis.call('EXISTS', KEYS[1]) == 0 then
return -1 -- Counter key 유실 감지 → Java에서 DB MAX(id)로 복구
end
local mid = redis.call('INCR', KEYS[1])
local cur = redis.call('GET', KEYS[2])
if cur == false or mid > tonumber(cur) then
redis.call('SET', KEYS[2], tostring(mid), 'EX', tonumber(ARGV[1]))
else
redis.call('EXPIRE', KEYS[2], tonumber(ARGV[1]))
end
return mid“현재 값보다 클 때만 저장.” 이 불변식이 동시성 환경에서도 최신 메시지 ID의 정합성을 보장합니다.
왜 스트림을 둘로 분리했는가
XADD-first로 전환하면서, Consumer의 역할이 두 가지로 분화됐습니다.
- Instance Stream: 실시간 WebSocket 전달 (순서 보장 필수)
- Pipeline Stream: DB 저장 + 푸시 알림 (순서 무관, 배치 가능)
| 단일 스트림 | 분리 스트림 | |
|---|---|---|
| DB 실패 → 실시간 차단 | 가능 | 격리 |
| 배치 최적화 | 불가 | Pipeline만 적용 |
| Consumer 독립 확장 | 불가 | 각각 독립 |
분리 후 측정한 데이터가 이 결정을 뒷받침합니다.
| Stream | P95 |
|---|---|
| Instance (실시간 전달) | 11,570 ms |
| Pipeline (DB 저장) | 12.31 ms |

약 1000배 차이. 같은 스트림에 있었다면, Pipeline의 12ms가 Instance의 11초에 가려져 보이지 않았을 것입니다.
Pipeline Consumer는 Spring의 StreamMessageListenerContainer를 걷어내고, Lettuce RedisStreamCommands를 직접 사용하는 Batch Consumer로 교체했습니다. XREADGROUP(COUNT 50) → batch DB INSERT → batch XACK로 150 roundtrips를 3으로 줄였습니다.
Queue Wait Time 99.98%
Stream 분리 후, Instance Consumer의 onMessage 처리 시간을 Phase별로 분해했습니다.
| Phase | avg |
|---|---|
| Presence (MGET) | 0.28 ms |
| Broadcast (convertAndSend) | 0.21 ms |
| ACK (XACK) | 0.24 ms |
| onMessage Total | 0.93 ms |
0.93밀리초. 그런데 E2E Delivery P95는 4,326ms.

99.98%가 큐 대기 시간. onMessage를 아무리 최적화해도 전체 latency의 0.02%.
코드 최적화의 문제가 아니라 큐잉 이론의 문제였습니다. Consumer 수를 늘려야 했습니다.
Partition & Concurrency
어떤 축으로 확장할 것인가
Kafka에서는 1 partition = 1 consumer 제약으로, 처리량을 늘리려면 파티션을 추가해야 합니다. Redis Streams는 같은 스트림에 여러 consumer가 경쟁 소비할 수 있습니다. concurrency 증가는 환경변수 하나로 즉시 적용되지만, partition 증가는 stream 키 변경과 미처리 메시지 마이그레이션이 필요합니다. concurrency를 먼저 올리고, 그다음 partition.
roomId 해싱과 순서 보장
Producer는 roomId % 4로 같은 채팅방의 메시지를 항상 같은 파티션에 라우팅합니다.
chat:stream:instance:partition:0 ← roomId % 4 == 0
chat:stream:instance:partition:1 ← roomId % 4 == 1
chat:stream:instance:partition:2
chat:stream:instance:partition:3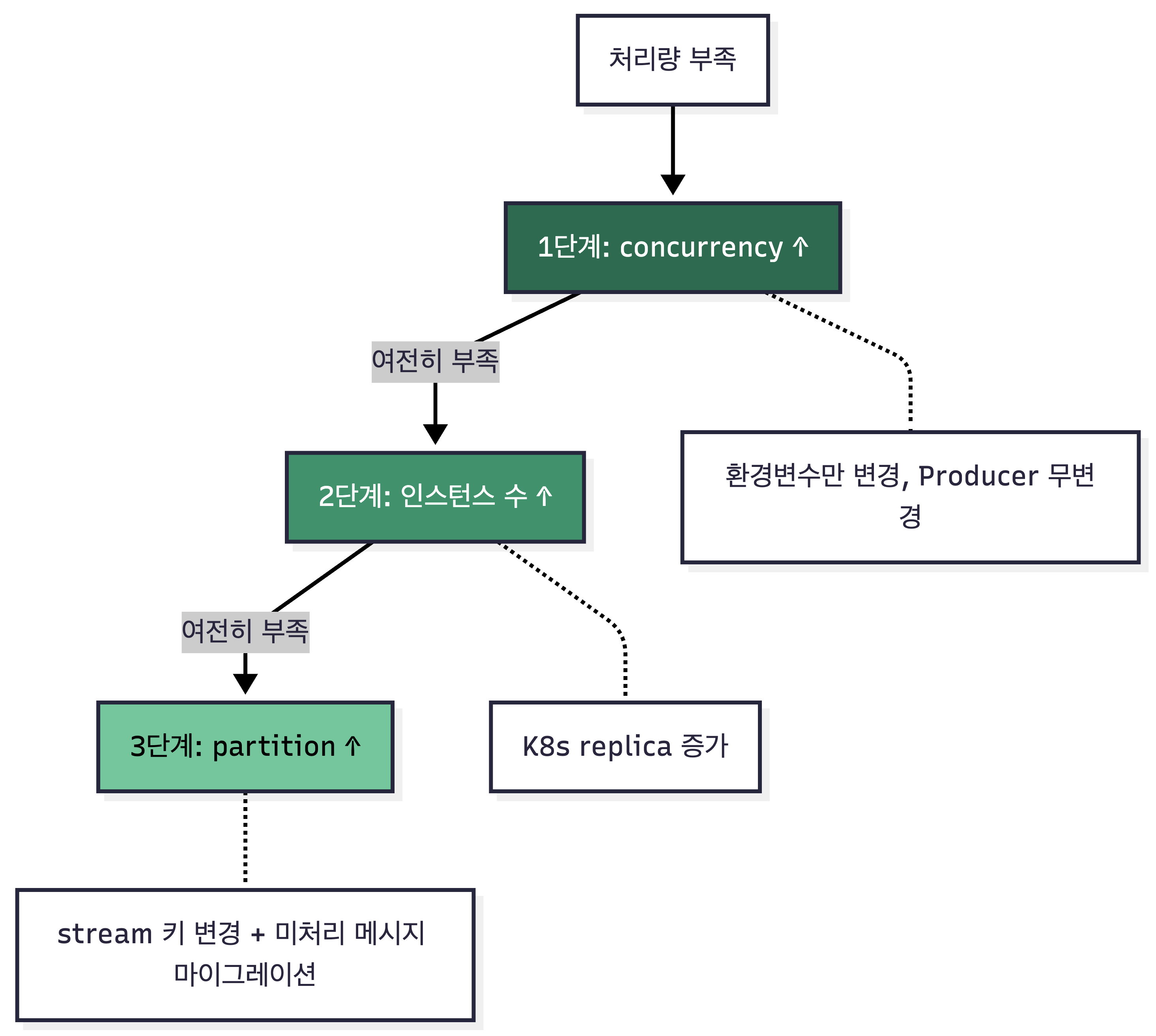
partition 수는 부하테스트를 반복하며 결정했습니다. vCPU 2 환경에서 partition=2는 병렬도 부족, partition=8은 context switching 오버헤드가 이득을 상쇄. partition=4에서 1000VU E2E avg 14ms로 안정적이었습니다.
Consumer 유형별 전략
| Consumer | 순서 보장 | concurrency | 이유 |
|---|---|---|---|
| Instance (WebSocket) | 필수 | 1 | 순서 역전 → UX 파괴 |
| Pipeline (DB save) | 불필요 | 2 | IO-bound, 순서 무관 |
Instance consumer는 파티션마다 전용 단일 스레드 executor로 FIFO 순서를 보장합니다.
ThreadPoolExecutor executor = new ThreadPoolExecutor(
1, 1, 0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<>(1000),
r -> new Thread(r, "redis-stream-" + consumerName)
);Pipeline consumer는 같은 파티션에 consumer 2개를 붙여, 하나가 DB IO를 기다리는 동안 다른 하나가 다음 배치를 처리합니다. 결과적으로 Instance 4 threads, Pipeline 8 threads.
Pool 경합의 근본 해결을 위해 Lettuce async 멀티플렉싱으로 전환하여 Pool 자체를 제거했습니다. (상세는 별도 글에서 다룹니다)
결과
| 메트릭 | Before | After (1000VU) |
|---|---|---|
| Processing Rate | 12% | 100% |
| Delivery avg | 측정 불가 (Consumer 기아) | 0.33 ms |
| 메시지 유실 | 48,573건 | 0건 |
| 접속 용량 | 1000VU 미달 | 3,500VU |
| HikariCP Acquire max | 2,243 ms | 3.4 ms |

Netty나 Kafka 없이, Spring Boot + Tomcat + Redis Streams 위에서 코드 레벨 최적화만으로 달성한 결과입니다.
되돌아보며
병목은 이동합니다. Redis 풀 → HikariCP → Consumer 처리율 → 큐 대기 시간. 하나를 해결할 때마다 다음 병목이 드러났고, “이것만 고치면 끝”이라는 생각은 매번 틀렸습니다.
메트릭에 태그를 붙여야 합니다. 서로 다른 성격의 consumer latency가 같은 Timer에 합산되면, 유효한 개선이 가려집니다. stream_type 태그 하나를 추가하기 전에는 유효한 전환을 무효한 것으로 오인했습니다.