
GPS 좌표 하나로는 “어디”인지 알 수 없습니다. 행정구역, POI, 도로 정보를 PostGIS 공간 쿼리로 통합하고, GiST 인덱스 최적화로 1500ms → 45ms까지 개선한 역지오코딩 시스템 구축 과정을 공유합니다.
들어가며
저는 GPS 기반 차량 트래킹 서비스에서 위치 데이터를 활용한 공간 분석 시스템을 설계하고 구축하는 역할을 맡았습니다.
서비스의 핵심 기능 중 하나는 차량의 GPS 좌표를 받아 “이 차량이 지금 어디에 있는가”를 사람이 이해할 수 있는 형태로 변환하는 것이었습니다. (100.5018, 13.7563)이라는 숫자 쌍을 보고 이것이 태국 방콕의 프라나콘구인지 즉시 파악할 수 있는 사람은 없습니다. 좌표에 맥락을 부여하는 역지오코딩 시스템이 필요했습니다.
이 글에서는 HDX/OSM 대용량 Geo 데이터의 자동화 적재 파이프라인 구축, PostGIS 공간 쿼리 기반 API 설계, 그리고 GiST 인덱스 최적화를 통한 성능 개선까지의 과정을 공유합니다.
기술 스택: PostgreSQL 16.9 · PostGIS 3.4.1 · ogr2ogr (GDAL 3.x) · osm2pgsql 1.7.0 인프라: Ubuntu 20.04 · Docker (Multi-stage Build) · 2 vCPU · 4GB RAM
배경: GPS 좌표의 한계
GPS 수신기가 보내는 데이터는 위도와 경도, 두 개의 숫자입니다.
위도: 13.7563, 경도: 100.5018이 좌표가 태국 방콕 프라나콘구의 왕궁 근처라는 사실은 지도 위에 찍어보기 전까지 알 수 없습니다. 차량 관제 시스템에서 운영자가 매번 좌표를 지도에서 확인해야 한다면, 수백 대의 차량을 실시간으로 모니터링하는 것은 불가능합니다.
가장 쉬운 해결책은 Google Maps Geocoding API를 사용하는 것입니다. 하지만 두 가지 제약이 있었습니다.
| 제약 | 상세 |
|---|---|
| 비용 | 건당 과금 구조, 차량 수백 대가 수초 간격으로 좌표를 전송하면 호출량이 급증 |
| 네트워크 의존성 | 외부 API 장애 시 위치 정보 전체가 중단되는 단일 장애점 |
상용 API 의존 없이 자체 데이터베이스 기반으로 역지오코딩 시스템을 구축하기로 결정했습니다. 오픈 데이터(HDX, OpenStreetMap)와 PostGIS를 활용하면, 행정구역부터 POI, 도로명까지 포괄하는 위치 정보를 무료로 제공할 수 있습니다.
데이터 파이프라인: 대용량 Geo 데이터 자동화 적재
데이터소스 3종
역지오코딩에 필요한 데이터는 성격이 서로 다른 세 곳에서 수집했습니다.
| 데이터소스 | 제공 기관 | 데이터 성격 | 포맷 |
|---|---|---|---|
| HDX | UN OCHA | 공식 행정구역 경계 (ADM0~ADM3) | Shapefile (.shp) |
| OpenStreetMap | OSM Foundation | 크라우드소싱 POI, 도로, 건물 | PBF (.osm.pbf) |
| Marine Regions | Flanders Marine Institute | 해양 경계 (EEZ, 해역명) | Shapefile |
HDX는 UN이 관리하는 공식 행정구역 데이터로, 태국 기준 77개 도/특별시(ADM1), 878개 군/구(ADM2), 7,255개 읍/면/동(ADM3)까지의 경계 polygon을 제공합니다. OSM은 레스토랑, 병원, 학교 같은 POI와 도로 네트워크를 담고 있습니다. 두 데이터소스의 역할이 명확히 분리됩니다 — HDX가 “어느 행정구역인가”를, OSM이 “구체적으로 어떤 장소/도로인가”를 답합니다.
ETL 파이프라인 설계
전체 파이프라인은 Shell 스크립트 기반으로 자동화했습니다. main.sh가 오케스트레이터 역할을 하며, 각 데이터소스별 Extract → Transform → Load를 순차 실행합니다.
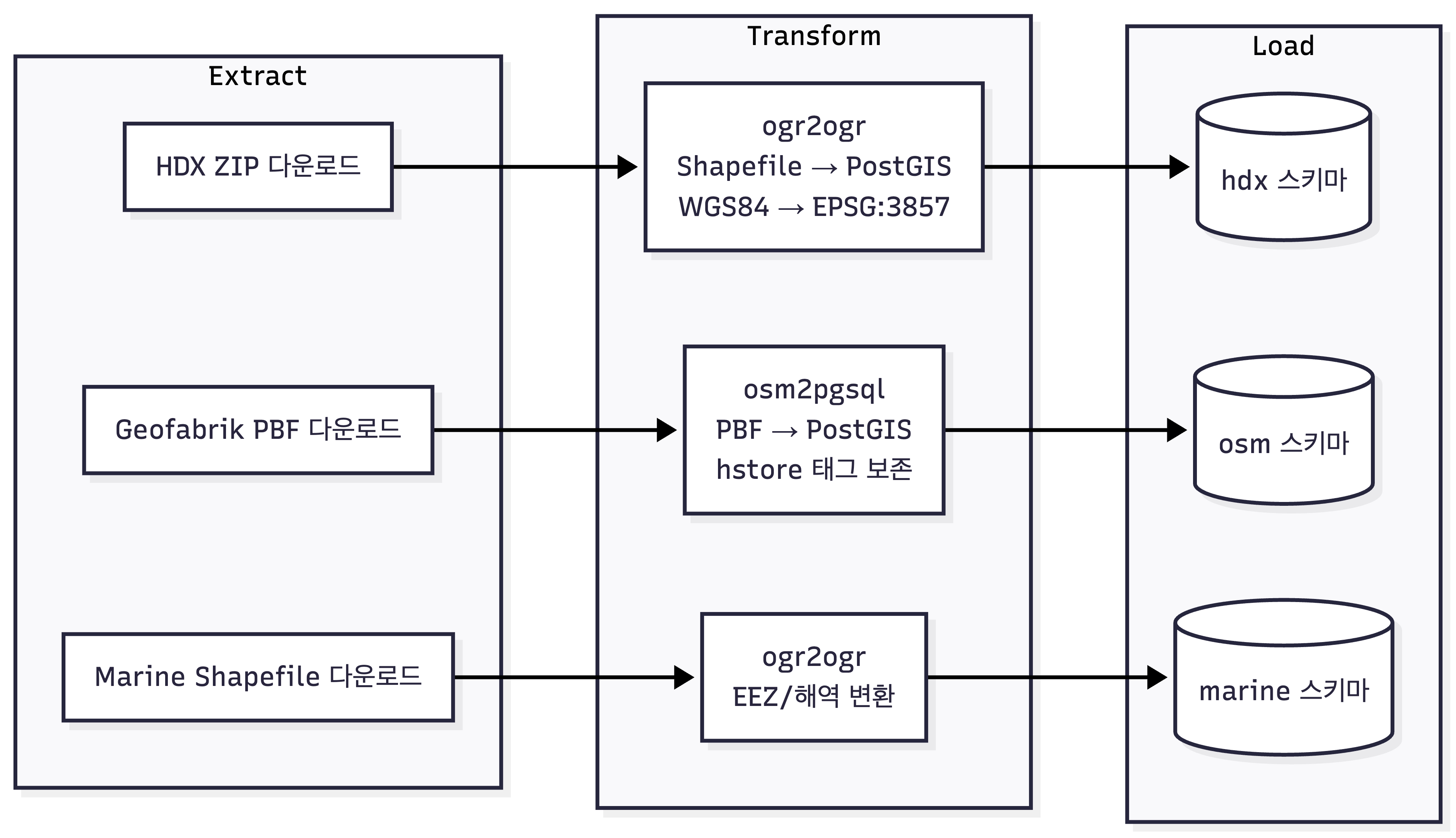
각 단계의 핵심 처리를 정리하면 다음과 같습니다.
| 데이터소스 | Extract | Transform | Load |
|---|---|---|---|
| HDX | ZIP 다운로드 → 압축 해제 → ADM 레벨별 Shapefile 분류 | WGS84(EPSG:4326) → Web Mercator(EPSG:3857) 좌표 변환, ST_MakeValid로 지오메트리 수정 | ogr2ogr로 ADM0→ADM1→ADM2→ADM3 순차 bulk 로딩 |
| OSM | Geofabrik에서 국가별 PBF 다운로드 | osm2pgsql이 PBF 파싱과 동시에 PostGIS 테이블 생성 | hstore 태그 보존, point/line/polygon/roads 4개 테이블 자동 생성 |
| Marine | EEZ, 해역 Shapefile 다운로드 | ogr2ogr로 좌표 변환 | marine 스키마에 적재 |
HDX 데이터가 없는 국가(주로 선진국)에는 GeoBoundaries(GBD) 데이터를 대체 사용합니다. GBD는 속성 필드명이 다르므로(shapeName, shapeID 등), 내부 표준 스키마(HDX 형식)로 변환하는 Transform 단계가 추가됩니다.
GBD Transform: shapeName → adm*_name_en, shapeID → adm0_code국가 확장성
파이프라인의 핵심 설계 원칙은 국가 확장성입니다. config.env에서 국가코드와 국가명만 변경하면 다른 나라의 데이터도 동일한 파이프라인으로 적재할 수 있습니다.
# config.env — 국가만 변경하면 전체 파이프라인 재사용
export COUNTRY_NAME="thailand"
export COUNTRY_CODE="TH"실제로 태국, 호주, 베트남 등 여러 국가의 데이터를 이 파이프라인으로 적재했습니다.
데이터베이스 설계: 공간 데이터 통합 스키마
3개 스키마 분리 전략
데이터소스별 성격이 다르므로, 스키마를 분리하여 관리합니다.
| 스키마 | 목적 | 주요 테이블 |
|---|---|---|
hdx | 행정구역 경계 관리 | hdx_admin_boundaries |
osm | POI, 도로, 건물 등 지도 데이터 | planet_osm_point, planet_osm_line, planet_osm_polygon, planet_osm_roads |
marine | 해양 경계 데이터 | eez_boundaries, sea_areas |
public | 통합 API 함수 | get_combined_location_info(), get_full_location_info() |
통합 함수는 public 스키마에 두어, 호출하는 쪽에서 내부 스키마 구조를 알 필요 없이 좌표만 넘기면 됩니다.
hdx_admin_boundaries 테이블
행정구역 데이터의 핵심 테이블입니다. ADM0(국가)부터 ADM3(읍/면/동)까지의 계층 구조를 단일 테이블에 저장합니다.
CREATE TABLE hdx.hdx_admin_boundaries (
id SERIAL PRIMARY KEY,
admin_level INTEGER NOT NULL, -- 0: 국가, 1: 도, 2: 군/구, 3: 읍/면/동
adm0_code VARCHAR(10), -- 국가 코드 (TH, AU, VN)
adm0_name_en VARCHAR(100), -- Thailand
adm1_code VARCHAR(10), -- 도/시 코드
adm1_name_en VARCHAR(100), -- Bangkok
adm2_code VARCHAR(10), -- 군/구 코드
adm2_name_en VARCHAR(100), -- Phra Nakhon
adm3_code VARCHAR(10), -- 읍/면/동 코드
adm3_name_en VARCHAR(100), -- Phra Borom Maha Ratchawang
data_source VARCHAR(50) DEFAULT 'HDX',
geom GEOMETRY(MULTIPOLYGON, 3857) -- Web Mercator 좌표계
);admin_level 컬럼으로 계층을 구분하고, 각 행정구역의 경계는 MULTIPOLYGON 타입의 geom 컬럼에 저장됩니다. 좌표계는 WGS84(EPSG:4326)에서 Web Mercator(EPSG:3857)로 변환하여 저장합니다. 미터 단위 거리 계산이 필요한 공간 쿼리에서 좌표 변환 오버헤드를 제거하기 위함입니다.
OSM 테이블 구조
OSM 데이터는 osm2pgsql이 자동 생성하는 4개의 표준 테이블에 저장됩니다.
| 테이블 | 저장 대상 | 역지오코딩 활용 |
|---|---|---|
planet_osm_point | POI (레스토랑, 병원, 학교 등) | 가장 가까운 POI 검색 |
planet_osm_line | 도로, 강, 철도 | 도로명 + 도로 유형 추출 |
planet_osm_polygon | 건물, 공원, 항구 | 좌표가 포함된 장소명 추출 |
planet_osm_roads | 주요 도로 (성능 최적화용 서브셋) | 빠른 도로 검색 |
모든 테이블은 tags 컬럼(hstore 타입)을 통해 다국어 명칭(name:en, name:th), 시설 분류(amenity, shop), 주소 정보(addr:street) 등을 동적으로 저장합니다.
API 설계: 좌표 하나로 맥락을 읽다
함수 호출 계층
최종 API는 하나의 진입점(get_combined_location_info)으로 통합됩니다. 내부적으로 해양/육지를 자동 판별한 뒤, 적절한 하위 함수를 호출합니다.
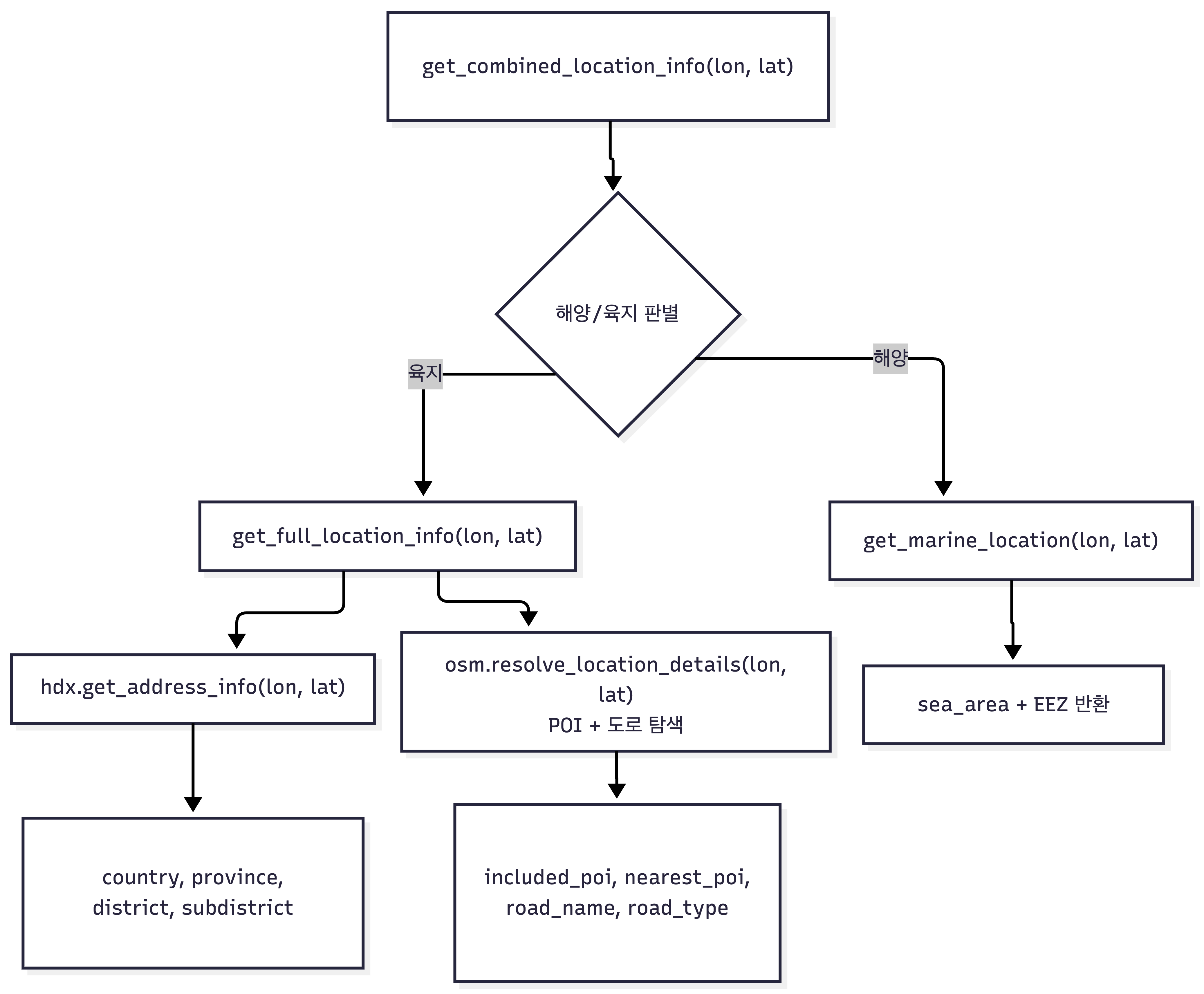
get_address_info: 행정구역 매칭
좌표가 어느 행정구역에 속하는지 판별하는 함수입니다. ST_Contains로 좌표를 포함하는 polygon을 찾습니다.
-- hdx.get_address_info 핵심 로직
SELECT json_build_object(
'country', MAX(CASE WHEN admin_level = 0 THEN adm0_name_en END),
'province', MAX(CASE WHEN admin_level = 1 THEN adm1_name_en END),
'district', MAX(CASE WHEN admin_level = 2 THEN adm2_name_en END),
'subdistrict', MAX(CASE WHEN admin_level = 3 THEN adm3_name_en END)
)
FROM hdx.hdx_admin_boundaries
WHERE ST_Contains(geom, ST_Transform(ST_SetSRID(ST_Point(lon, lat), 4326), 3857));입력 좌표를 WGS84(4326)에서 Web Mercator(3857)로 변환한 뒤, ST_Contains로 해당 좌표를 포함하는 모든 행정구역을 조회합니다. ADM0~ADM3 레벨이 각각 다른 행에 저장되어 있으므로, CASE WHEN으로 각 레벨을 분리하고 MAX로 집계합니다.
resolve_location_details: 3단계 탐색
행정구역보다 세밀한 위치 정보 — “이 좌표가 어떤 건물/시설 안에 있는가, 가장 가까운 POI는 무엇인가, 어떤 도로 위인가” — 를 3단계로 탐색합니다. 함수 진입 시, 입력 좌표를 Web Mercator로 변환하고 50m·100m 버퍼를 미리 계산해둡니다.
[1] 포함된 Polygon 검색
좌표를 포함하는 가장 구체적인 장소를 찾습니다.
polygon 테이블에서:
1. bbox 겹침 필터 (way && point) ← GiST 인덱스로 후보 축소
2. 실제 포함 판별 (ST_Contains)
3. 면적 < 400km² ← 대형 행정구역 제외
4. 면적 오름차순 정렬 → 가장 작은 polygon 1건 반환왜 400km²인가? OSM polygon에는 국가나 대형 행정구역도 포함되어 있습니다. 면적 제한 없이 검색하면 “Thailand” 같은 거대 polygon이 매칭됩니다. 400km² 필터로 이를 제외하고, 건물·공원·항구 등 의미 있는 규모의 장소만 반환합니다. 면적순 정렬 덕분에 왕궁 좌표에서는 “방콕”이 아닌 “Grand Palace”가 반환됩니다.
[2] 가장 가까운 POI 검색 (100m 이내)
[1]에서 포함된 장소를 찾았더라도, 주변에 더 구체적인 POI가 있을 수 있습니다.
사전 계산된 100m 버퍼로 인덱스 스캔:
point 테이블 → 100m 이내 POI 후보
UNION ALL
polygon 테이블 → 100m 이내 POI 후보 ([1] 결과 제외)
→ 거리순 정렬, 가장 가까운 1건 반환Point(상점, 시설)와 Polygon(건물, 공원) POI를 UNION ALL로 합친 뒤 거리순 정렬하여, 데이터 유형에 관계없이 가장 가까운 POI 하나를 반환합니다.
[3] 도로 정보 (50m 이내)
사전 계산된 50m 버퍼로 인덱스 스캔:
line 테이블 → highway IS NOT NULL인 도로 후보
→ 이름 있는 도로 우선, 그 중 가장 가까운 1건
→ (road_name, road_type) 반환이름 있는 도로를 우선하되, 주변에 이름 있는 도로가 없으면 도로 유형(secondary, residential 등)만이라도 반환합니다.
실제 반환값 예시
방콕 왕궁 좌표(100.5018, 13.7563)로 호출한 결과입니다.
{
"location_type": "land",
"data": {
"coordinates": { "longitude": 100.5018, "latitude": 13.7563 },
"administrative": {
"country": "Thailand",
"province": "Bangkok Province",
"district": "Phra Nakhon District",
"subdistrict": "Phra Borom Maha Ratchawang Tambon"
},
"details": {
"included_poi": "Grand Palace",
"nearest_poi": "Wat Phra Kaew",
"road_name": "Thanon Sanam Chai",
"road_type": "primary"
},
"timestamp": "2025-08-08T13:38:57.881409+09:00"
}
}숫자 두 개에 불과했던 GPS 좌표가, 행정구역(4단계) + 포함 장소 + 가까운 POI + 도로 정보를 갖춘 맥락 있는 위치 정보로 변환됩니다. 해양 좌표를 입력하면 location_type: "marine"과 함께 해역명, EEZ 정보가 반환됩니다.
성능 최적화: 1500ms → 45ms
초기 문제: 순차 스캔으로 1500ms
통합 함수를 처음 배포했을 때, 단일 좌표 조회에 약 1500ms가 소요됐습니다. EXPLAIN ANALYZE를 실행해보니 원인은 명확했습니다 — 공간 인덱스 없이 전체 테이블을 Sequential Scan하고 있었습니다.
태국 기준 hdx_admin_boundaries에 8,211개의 polygon, planet_osm_polygon에 수십만 개의 polygon이 저장되어 있습니다. 매 쿼리마다 이 모든 polygon에 대해 ST_Contains 연산을 수행하니, 응답 시간이 초 단위로 올라가는 것은 당연한 결과였습니다.
GiST 공간 인덱스 적용
PostGIS에서 공간 검색 성능의 핵심은 GiST(Generalized Search Tree) 인덱스입니다. GiST는 각 geometry의 바운딩 박스(MBR, Minimum Bounding Rectangle)를 트리 구조로 관리하여, 전체 스캔 없이 후보를 빠르게 좁혀줍니다.
-- 공간 인덱스 생성 (GiST)
CREATE INDEX idx_hdx_admin_geom ON hdx.hdx_admin_boundaries USING GIST (geom);
CREATE INDEX idx_osm_point_way ON osm.planet_osm_point USING GIST (way);
CREATE INDEX idx_osm_line_way ON osm.planet_osm_line USING GIST (way);
CREATE INDEX idx_osm_polygon_way ON osm.planet_osm_polygon USING GIST (way);
CREATE INDEX idx_osm_roads_way ON osm.planet_osm_roads USING GIST (way);
-- 속성 인덱스 (B-Tree) — 자주 필터링하는 컬럼
CREATE INDEX idx_hdx_admin_level ON hdx.hdx_admin_boundaries (admin_level);
CREATE INDEX idx_osm_line_highway ON osm.planet_osm_line (highway);쿼리 최적화 전략
인덱스만으로는 충분하지 않았습니다. ST_Contains는 정확한 포함 여부를 판별하는 고비용 연산이므로, 인덱스가 후보를 줄인 뒤에도 실제 geometry 비교에 시간이 걸립니다. 다음 네 가지 전략을 조합하여 추가 최적화를 수행했습니다.
1. && 연산자 + ST_Contains 조합
WHERE way && geom_3857 -- 1차: bbox 필터 (GiST 인덱스만 사용, 매우 빠름)
AND ST_Contains(way, geom_3857) -- 2차: 정확한 포함 판별 (후보만 대상)&& 연산자는 바운딩 박스 겹침만 검사하므로 GiST 인덱스를 100% 활용합니다. 이 1차 필터로 후보를 극소수로 줄인 뒤, ST_Contains가 정확한 포함 여부만 확인합니다. ST_Contains 단독 사용 대비 후보 수를 수십~수백 분의 1로 줄이는 효과가 있습니다.
2. 버퍼 사전 계산
buffer_50m := ST_Buffer(geom_3857, 50);
buffer_100m := ST_Buffer(geom_3857, 100);ST_DWithin(way, geom, 100)은 매 row마다 거리를 계산합니다. 대신 좌표 주변에 미리 100m 버퍼 polygon을 생성해두고, way && buffer_100m으로 인덱스 스캔을 유도합니다. 버퍼 생성은 1회, 이를 활용한 검색은 N회이므로, POI와 도로를 각각 탐색하는 구조에서 효과가 큽니다.
3. ORDER BY ST_Area(way) — 가장 작은 polygon 우선
좌표를 포함하는 polygon이 여러 개일 때(예: “태국 > 방콕 > 프라나콘구 > 왕궁”), 면적이 가장 작은 polygon이 가장 구체적인 장소입니다. ORDER BY ST_Area(way) LIMIT 1로 가장 세밀한 결과를 반환합니다.
4. 400km² 면적 필터
AND ST_Area(ST_Transform(way, 4326)::geography) < 400000000 -- 400km² = 4억 m²OSM polygon에는 국가 경계, 대형 행정구역 등 수만 km² 규모의 polygon이 포함되어 있습니다. 이런 polygon은 ST_Contains에서 매칭되더라도 의미 있는 정보가 아닙니다. 면적 상한으로 거대 polygon을 사전 제외하여 불필요한 연산을 줄입니다.
Before / After
| 메트릭 | Before | After | 변화 |
|---|---|---|---|
| 응답 시간 | ~1,500ms | ~45ms | 97% 감소 (33배) |
| 실행 계획 | Sequential Scan | Index Scan (GiST) | — |
| 인덱스 | 없음 | GiST (공간) + B-Tree (속성) | — |
| 쿼리 패턴 | ST_Contains 단독 | && + ST_Contains 조합 | bbox 사전 필터링 |
| 버퍼 전략 | 매 row 거리 계산 | 사전 계산된 buffer polygon | 1회 계산, N회 재사용 |
핵심은 “비싼 연산 전에 싼 연산으로 후보를 줄인다”는 원칙입니다. GiST 인덱스가 바운딩 박스로 1차 필터링하고, && 연산자가 2차 필터링하고, ST_Contains가 최종 확인합니다. 이 3단계 파이프라인이 1500ms를 45ms로 줄였습니다.
결과
정량적 성과
| 항목 | 수치 |
|---|---|
| 역지오코딩 응답 시간 | 1,500ms → 45ms (97% 개선) |
| 행정구역 데이터 | 태국 기준 8,211개 polygon (ADM0~ADM3) |
| OSM 데이터 | point 수십만, polygon 수십만, line 수십만 건 |
| 해양 데이터 | EEZ 경계 + 해역명 |
| API 커버리지 | 행정구역 + POI + 도로 + 해양 통합 |
| 외부 API 의존 | Google Maps 0건 → 완전 자체 운영 |
국가 확장 현황
config.env의 국가코드만 변경하여 동일한 파이프라인으로 적재한 국가 목록입니다.
| 국가 | 데이터소스 | 비고 |
|---|---|---|
| 태국 (TH) | HDX + OSM | 1차 구축, 전체 기능 검증 완료 |
| 호주 (AU) | GBD + OSM | HDX 미제공 → GBD 대체 사용 |
| 베트남 (VN) | HDX + OSM | 2차 확장 |
마치며
GPS 좌표 하나에서 시작해, 행정구역·POI·도로·해양 정보를 통합 제공하는 역지오코딩 시스템을 구축했습니다. 이 과정에서 얻은 핵심 교훈은 세 가지입니다.
공간 인덱스는 선택이 아닌 필수입니다. 수만 개의 polygon에 대해 ST_Contains를 인덱스 없이 실행하면 초 단위 응답이 됩니다. GiST 인덱스와 && 연산자 조합만으로 33배 성능 차이가 발생했습니다. 공간 데이터를 다룬다면 테이블 생성 직후 GiST 인덱스부터 만들어야 합니다.
데이터 파이프라인의 자동화가 확장성을 결정합니다. 태국 데이터를 수동으로 한 번 적재하는 것은 어렵지 않습니다. 하지만 호주, 베트남, 그다음 국가로 확장할 때마다 수작업을 반복한다면 운영 비용이 선형으로 증가합니다. config.env 기반의 파라미터화된 파이프라인이 이 문제를 해결했습니다.
오픈 데이터의 조합이 상용 API를 대체할 수 있습니다. HDX(행정구역) + OSM(POI/도로) + Marine(해양)이라는 세 가지 오픈 데이터소스의 조합으로, Google Maps API의 역지오코딩 기능을 상당 부분 자체 구현할 수 있었습니다. 각 데이터소스는 단독으로는 불완전하지만, PostGIS 위에서 통합하면 강력한 위치 정보 시스템이 됩니다.
향후 계획
현재 스크립트 기반의 수동 실행 구조는 운영 환경에서 한계가 있습니다. Apache Airflow를 도입하여 국가별 ETL DAG를 자동 생성하고, 스케줄링·실패 재처리·모니터링을 체계화하는 것이 다음 과제입니다. 또한 자주 조회되는 좌표에 대한 Redis 캐싱 레이어를 추가하여, 반복 요청의 응답 시간을 sub-millisecond로 줄이는 것을 검토하고 있습니다.