k6로 1,000 VU를 쏟아부은 부하 테스트에서는 문제가 없었습니다. 그런데 실제 100명의 학생이 동시에 버튼을 누르는 순간, Grafana에는 어떤 그래프가 그려졌을까요?
들어가며
이전 글에서 Redis ZSet ZPOPMIN과 MySQL 조건부 UPDATE를 조합한 3중 방어선 아키텍처를 설계하고, k6 부하 테스트로 1,000 VU 동시 접속에서 overselling 0건을 검증했습니다.
그리고 2025년 10월 16일, 인천대학교 단과대학 간식나눔 행사에서 이 시스템이 실제 프로덕션 환경에 투입되었습니다. 드디어,, ! 실제 티케팅 날짜가 다가와, 100명의 학생이 CodIN 앱에서 동시에 “참여하기”를 눌렀고, 저는 Grafana 대시보드를 보며 그 순간을 지켜봤습니다.(많이 떨렸어요)
이 글에서는 부하 테스트가 아닌 실서비스 트래픽이 시스템에 어떤 영향을 미쳤는지, Grafana 지표를 기반으로 회고합니다.
아키텍처 설계에 대한 상세 내용은 이전 글을 참고해 주세요.
D-Day: 100장이 소진되기까지
행사 시각은 2025-10-16 16:00. DB의 created_at 타임스탬프로 참여 기록을 초 단위로 추적했습니다.
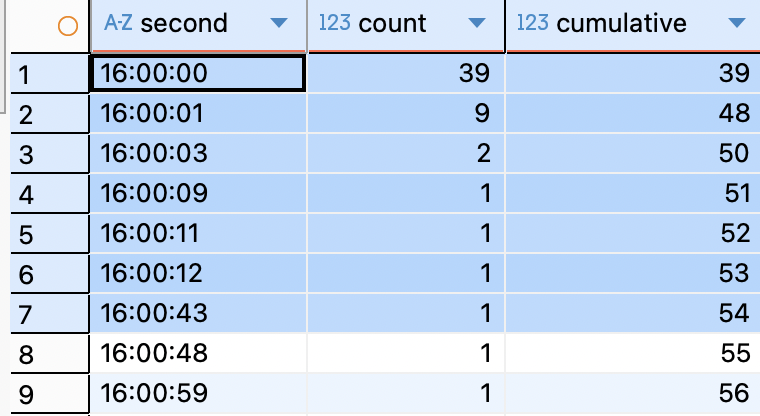
| 구간 | 소진 | 누적 | 비고 |
|---|---|---|---|
| 1초 이내 (16:00:00) | 39장 | 39 | 오픈과 동시에 39% 소진 |
| 3초 이내 | 11장 | 50 | 절반이 3초 만에 |
| 1분 이내 | 6장 | 56 | |
| 5분 이내 | 18장 | 74 | |
| 10분 이내 | 10장 | 84 | |
| 21분 이내 | 11장 | 95 | |
| 롱테일 (16:48~18:17) | 5장 | 100 | 마지막 5장은 2시간에 걸쳐 |
16:00:00, 오픈과 동시에 1초 만에 39명이 참여했습니다. 3초 후에는 절반인 50장이 소진되었고, 이후에는 1명씩 간헐적으로 들어오는 롱테일 패턴으로 전환됩니다.
k6 부하 테스트에서는 1,000 VU가 동시에 burst하는 균일한 패턴이었습니다. 하지만 실서비스에서는 전혀 다른 형태가 나타났습니다. 첫 3초의 급격한 burst + 이후 20분간의 점진적 소진 + 2시간에 걸친 롱테일. 부하 테스트에서는 볼 수 없는, 실제 사용자 행동이 만들어낸 트래픽 패턴입니다.
이 1초 만에 39명이 몰린 순간이 Grafana 대시보드에 어떤 흔적을 남겼는지 살펴보겠습니다.
Grafana로 본 인프라 지표
Docker Container — 인프라 리소스
총 22개의 컨테이너가 동작 중인 환경에서, 티케팅 시점의 리소스 변화를 관측했습니다.
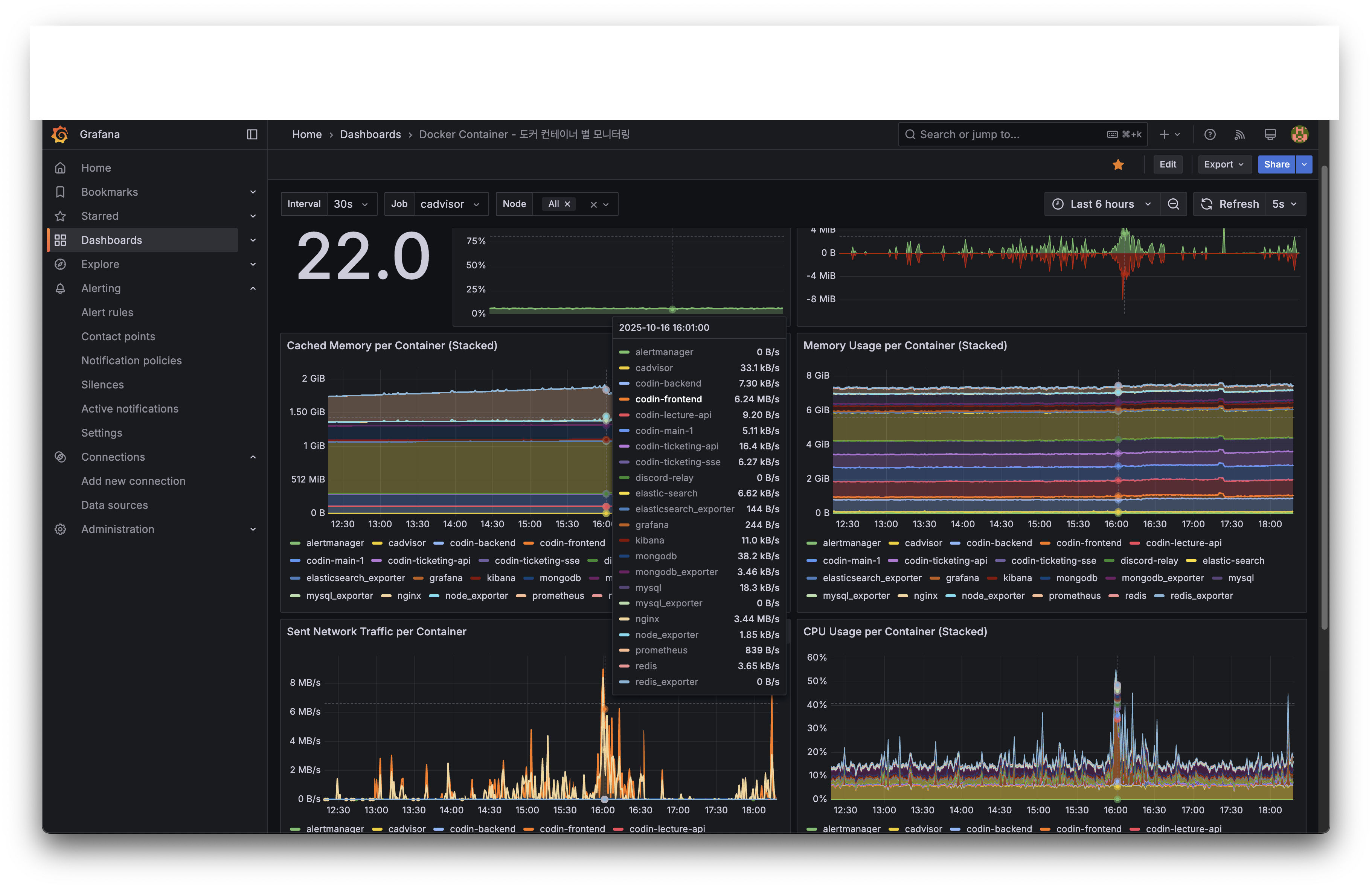
메모리
| 컨테이너 | 메모리 비중 | 비고 |
|---|---|---|
| codin-frontend | 38.8% | 전체 메모리의 최대 소비자 |
| codin-ticketing-api | 0.388% | ~31MB, 100명 접속에도 변화 미미 |
| codin-ticketing-sse | 0.462% | SSE 서버 |
| codin-backend | 0.332% | 커뮤니티 API |
전체 8GiB 중 codin-ticketing-api가 차지하는 비중은 0.388%에 불과합니다. 약 31MB 수준으로, 100명이 동시에 접근해도 메모리 사용량에 유의미한 변화가 없었습니다. JVM 힙이 충분히 여유 있는 상태에서 GC 압박 없이 처리된 것으로 판단됩니다.
네트워크
16:01 시점의 컨테이너별 네트워크 트래픽입니다.
| 컨테이너 | 트래픽 | 역할 |
|---|---|---|
| nginx | 3.44 MB/s | 리버스 프록시, 모든 요청의 진입점 |
| codin-frontend | 0.34 MB/s | 정적 리소스 서빙 |
| codin-ticketing-api | 16.4 kb/s | 티케팅 API 처리 |
| codin-ticketing-sse | 0.27 kb/s | 실시간 재고 push |
nginx에 트래픽이 집중(3.44 MB/s)되는 것은 리버스 프록시 구조의 자연스러운 패턴입니다. 주목할 점은 codin-ticketing-sse의 트래픽이 0.27 kb/s로 매우 낮다는 것인데, 이 부분은 뒤에서 다시 다루겠습니다.
CPU
16:00 전후로 CPU 사용률이 순간적으로 ~60%까지 치솟았습니다. 1초 만에 39명, 3초 만에 50명이 몰린 burst의 흔적입니다. 이후 트래픽이 롱테일로 전환되면서 수 초 내에 정상 수준으로 복귀했습니다.
MySQL — 커넥션과 쿼리 폭주
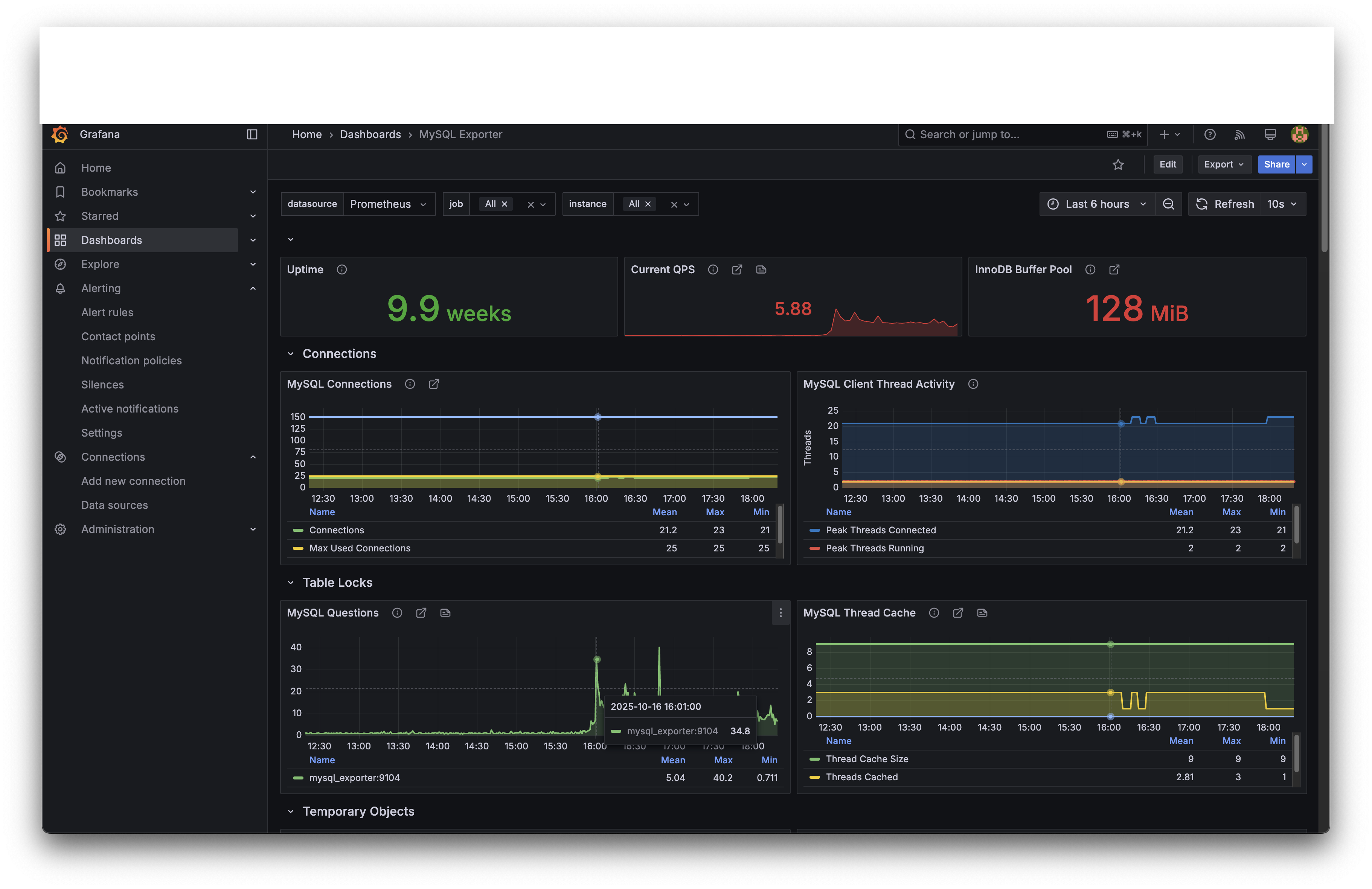
| 메트릭 | Mean | Max | Min |
|---|---|---|---|
| Connections | 21.2 | 23 | 21 |
| Max Used Connections | 25 | 25 | 25 |
| Questions (QPS) | 5.04 | 40.2 | 0.711 |
| Peak Threads Running | 2 | 2 | 2 |
QPS 스파이크: 평상시 대비 56배
평상시 QPS가 0.7 수준인 MySQL에 16:00~16:01 사이 40.2 QPS가 몰렸습니다. 56배 증가입니다. 앞서 확인한 타임라인에서 1초 만에 39명이 진입했는데, 각 요청마다 2차 방어(조건부 UPDATE) + 3차 방어(INSERT)가 실행되므로 최소 78 쿼리가 1초 안에 집중된 것입니다.
-- 2차 방어: 39명분의 조건부 UPDATE (16:00:00에 집중)
UPDATE stock SET remaining_stock = remaining_stock - 1
WHERE event_id = ? AND remaining_stock > 0;
-- 3차 방어: 39명분의 INSERT
INSERT INTO ticketing_participation (event_id, user_id, ticket_number, ...)
VALUES (?, ?, ?, ...);QPS 40.2는 이 burst를 초 단위로 평균 낸 수치입니다. 실제 순간 피크는 이보다 높았을 것입니다.
커넥션 풀 한계 근접
커넥션이 평소 21에서 최대 23까지 올랐고, Max Used Connections가 25로 설정 한도와 동일합니다. 100명 규모에서는 문제가 없었지만, 동시 접속자가 늘어나면 커넥션 풀이 병목이 될 수 있는 구간입니다.
다만 Peak Threads Running은 2로 일정한데, 이는 MySQL이 실제로 동시에 처리 중인 쿼리가 2개뿐이었다는 의미입니다. Redis ZPOPMIN이 1차 관문에서 대부분의 부하를 흡수하고, MySQL에는 성공한 요청만 도달했기 때문입니다.
Redis — 99.7% 캐시 히트율
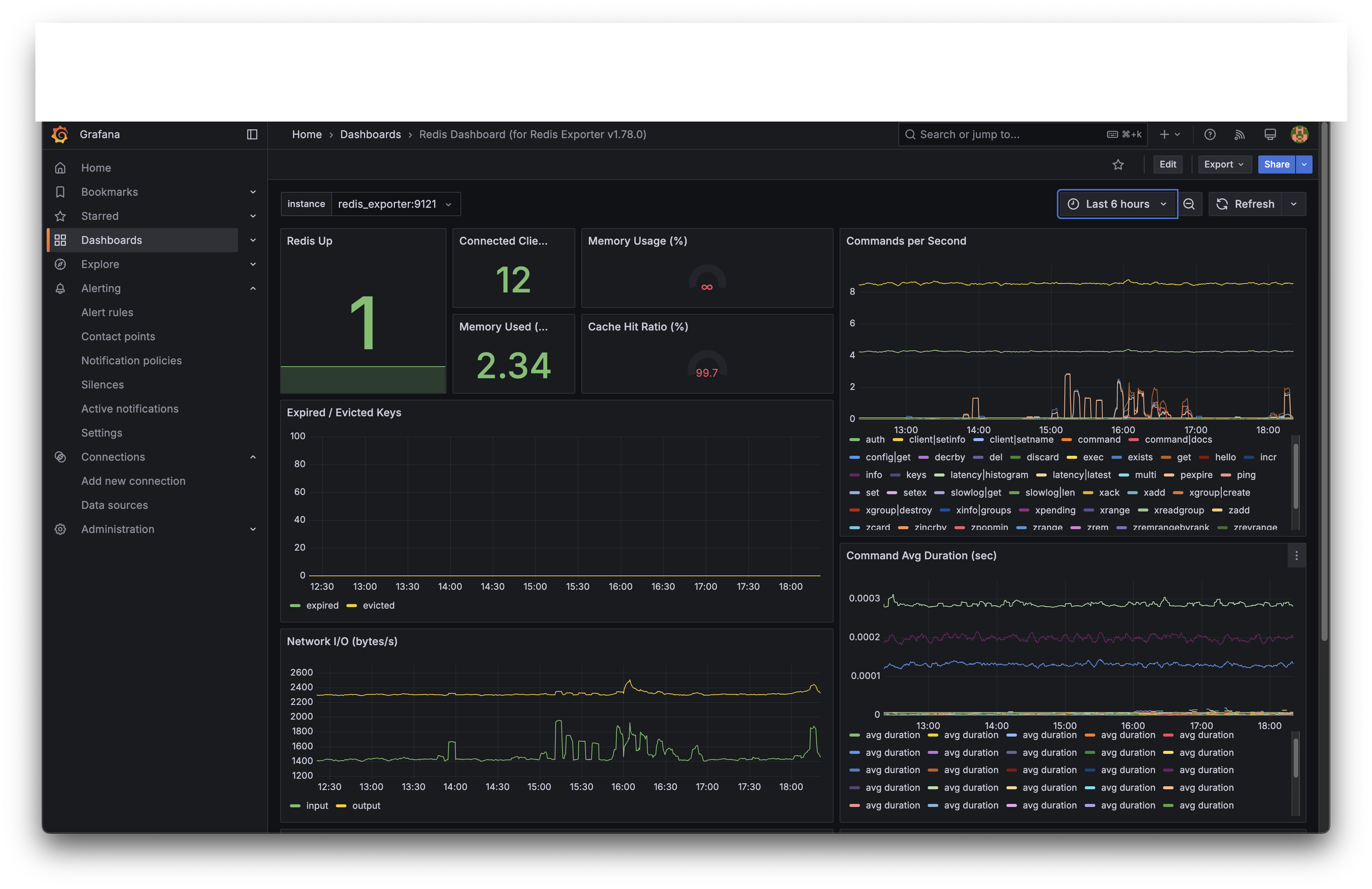
| 메트릭 | 값 |
|---|---|
| Connected Clients | 12 |
| Memory Used | 2.34 MB |
| Cache Hit Ratio | 99.7% |
| Commands/sec (peak) | ~6 |
| Command Avg Duration | <0.3ms |
캐시 히트율 99.7%
Redis가 거의 모든 조회 요청을 캐시에서 처리했습니다. 이벤트 정보와 참여 결과를 Redis에 캐싱한 덕분에, 이미 참여한 사용자가 다시 조회할 때 MySQL까지 가지 않고 Redis에서 바로 응답합니다.
Commands/sec: 피크 ~6
100명 동시 접속 대비 Redis commands/sec가 ~6으로 낮아 보일 수 있습니다. 이는 Grafana의 수집 간격(5s)으로 인해 순간 burst가 평균화된 결과입니다. 실제로는 ZPOPMIN 100회 + 캐시 조회/저장이 수 초 안에 집중되었을 것입니다.
Redis의 Command Avg Duration이 0.3ms 미만이라는 것은, 1차 방어선(ZPOPMIN)이 사실상 병목 없이 처리되었다는 의미입니다. k6 부하 테스트에서 측정한 Redis ZPOPMIN p95 4.01ms와 일관된 수치입니다.
회고
잘된 점
3중 방어선이 설계대로 동작했습니다. k6로 검증한 아키텍처가 실서비스에서도 그대로 작동한 것이 가장 의미 있는 성과입니다. 100명의 학생이 동시에 참여했고, overselling이나 중복 발급 없이 행사가 완료되었습니다.
Redis가 1차 관문 역할을 충실히 수행했습니다. Cache Hit Ratio 99.7%, Command Avg Duration 0.3ms 미만. Redis가 대부분의 부하를 흡수한 덕분에, MySQL의 Peak Threads Running은 2로 안정적이었습니다.
인프라 리소스에 여유가 있었습니다. ticketing-api 메모리 ~31MB, CPU 스파이크도 수 초 내 복귀. 100명 규모라면 현재 인프라로 충분히 감당할 수 있다는 것을 실서비스로 확인했습니다.
아쉬운 점
MySQL 커넥션 풀 설정이 빠듯합니다. Max Used Connections가 25로 설정 한도와 동일합니다. 100명에서는 문제가 없었지만, 200~300명 규모로 확장하면 커넥션 대기가 발생할 수 있습니다.
SSE 실시간 재고 push가 활발하지 않았습니다. codin-ticketing-sse의 네트워크 트래픽이 0.27 kb/s로, 실시간 재고 동기화가 기대만큼 활용되지 않았습니다. 클라이언트 측에서 SSE 연결을 적극적으로 활용하지 않았거나, Quartz 스케줄러의 폴링 주기가 burst 상황에서 충분히 빠르지 않았을 가능성이 있습니다.
Grafana 수집 간격의 한계. 5초 간격 수집으로는 티케팅처럼 수 초 안에 끝나는 burst 이벤트의 순간 피크를 정확히 포착하기 어렵습니다. Micrometer 커스텀 메트릭(각 방어 계층별 레이턴시)을 대시보드에 미리 구성해두었다면 더 세밀한 분석이 가능했을 것입니다.
다음에 개선할 것
| 항목 | 현재 | 개선 방향 |
|---|---|---|
| MySQL 커넥션 풀 | Max 25 | 부하 테스트 기반으로 50~100 수준으로 조정 |
| SSE 재고 push | Quartz 폴링 기반 | Redis Stream 기반 이벤트 드리븐으로 전환하여 재고 변화 즉시 push |
| Grafana 대시보드 | 기본 인프라 메트릭 | Micrometer 커스텀 메트릭(방어 계층별 레이턴시, 성공/실패 비율) 패널 추가 |
| 부하 규모 | 100명 실서비스 검증 | 300~500명 규모의 행사에서 추가 검증 |
마치며
부하 테스트에서 “1,000 VU, 0 에러”라는 결과를 얻었을 때, 시스템이 잘 동작한다고 확신하기 쉽습니다. 하지만 실서비스 트래픽은 k6 스크립트처럼 균일하지 않습니다. 1초에 39명이 몰렸다가 3초 만에 절반이 소진되고, 나머지는 2시간에 걸쳐 롱테일로 들어오는 — 이런 패턴은 부하 테스트 시나리오로 설계하기 어렵습니다.
이번 행사에서 100명의 실제 트래픽을 DB 타임스탬프와 Grafana로 관측한 경험은, 부하 테스트 수치만으로는 알 수 없는 것들을 보여주었습니다. MySQL 커넥션 풀 한도가 생각보다 빠듯하다는 것, SSE 파이프라인이 burst 상황에서 제 역할을 못했다는 것, Grafana 수집 간격이 순간 피크를 놓칠 수 있다는 것. 모두 실서비스에서만 발견할 수 있는 인사이트였습니다.
완벽하지는 않았지만, 설계한 시스템이 실제 사용자 앞에서 동작하는 것을 확인한 경험은 어떤 부하 테스트보다 값진 경험이었습니다.